independent-research
| Home | Independent Research | Last | Next |
Index
Mikolov, Tomas, Sutskever, Ilya, Chen, Kai, Corrado, Greg S, and Dean, Jeff. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pp. 3111–3119, 2013.
Motivation
Skip-gram model has achieved good performance in learning “high-quality vector representations of words from large amounts of unstructured text data”, which doesn’t require dense matrix multiplications. Based on skip-gram algorithm, the paper presents some extensions to imporove its performance: Hieralral softmax, negarive sampling and subsampling. Also shows that “the word vectors can be somewhat meaningful combined using just simple vector addition”.
Approach
Objective function of skip-gram:
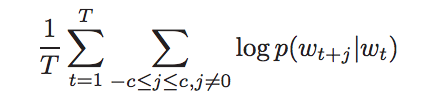
specifically, through softmax layer, p looks like:
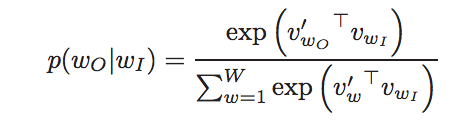
- Hierarchical softmax
Hierachical softmax uses a binary tree to present the output layer rather than a plat output of all W words for output dimension reduction. So that the computing would be much more efficient. The method is to replace the softmax layer with:
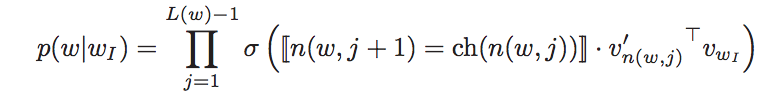
- Negative sampling
Another technique to speedup training process, inspired by Noise Constractive Estimation (NCE). The basic idea is sample one “accruate” data P(1) and k noise data P(0), the objective is to maximum their conditional log-likelihood:
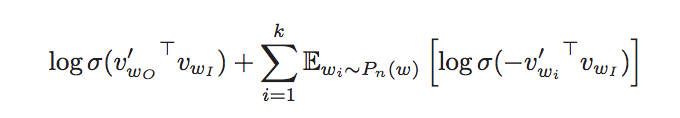
Note that the method is only for word representation rather than classification.
- Subsampling
There is imbalance between the rare and frequent words. The paper suggested a simple subsampling approach, assigning each wrod a discarded probability:
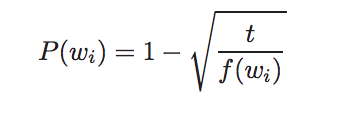
where f(wi) is the frequent of word wi and t is threshold.
The paper compares performances between Hierarchical Softmax (Huffman tree), Noise Contrastive Estimation, Negative Sampling and subsampling in skip-gram words and phrase training. Negative sampling outperformed others in words training while HS-subsampling combo achieved the best performances in phrases training.
The paper also shows that it is possible to meaningfully add words vectors element-wisely.