independent-research
Index
C. Cao, X. Liu, Y. Yang, Y. Yu, J. Wang, Z. Wang, Y. Huang, L. Wang, C. Huang, W. Xu, et al. Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks. In ICCV, 2015.
Motivation
The proposed network archtecture is to develop a “develop a computational feedback mechanism” which can help “better visualized and understand how deep neural network work, and capture visual attention on expected objects, even in images with cluttered background and multiple objects”.
Approach
A normal CNN archtecture includes:
-
Convolutional Layer
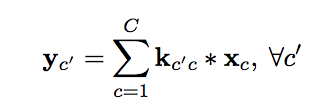
-
ReLU Layer
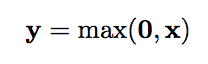
-
Max-Pooling Layer
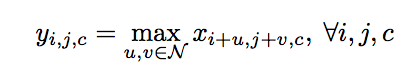
The work introduced a binary activation variable Z(0,1) instead of max() operation in ReLU layer and Max-Pooling layer, reinterpreting ReLU and Max-Pooling as
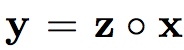
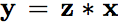
The paper also introduced a feedback model and its inference process. The feedback layer is stacked upon each ReLU layer, which looks like
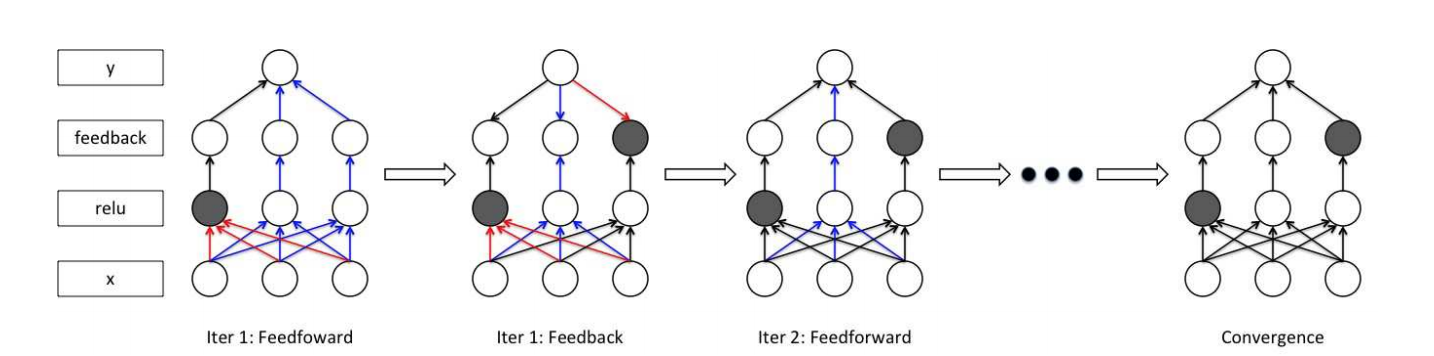
And the hidden neurons in feedback loops would be updated as
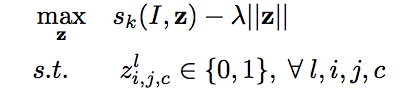
Since this leads to a NP hard problem, an apporiximation could be derived by applying a linear relaxation:
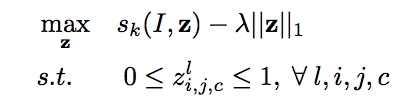
and then update the hidden variables via gradient ascent:
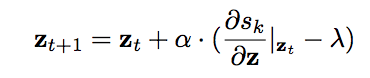
Dr. Chan’s concerns:
- The feedback loops cannot prevent multiple class sharing the same attention format
- not sure if there are weights from output to feedback layer